DeepAnalyze: Agentic Large Language Models for Autonomous Data Science
Abstract
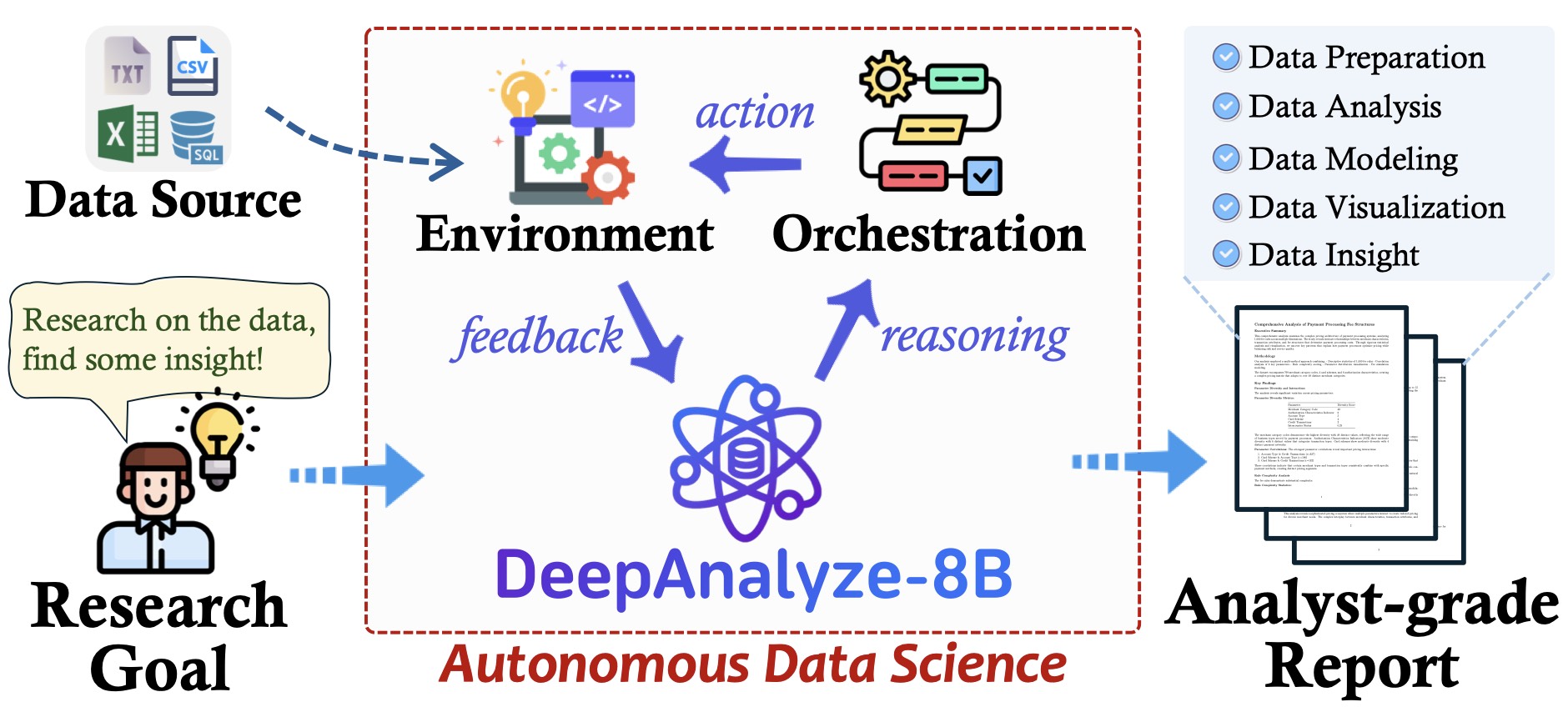
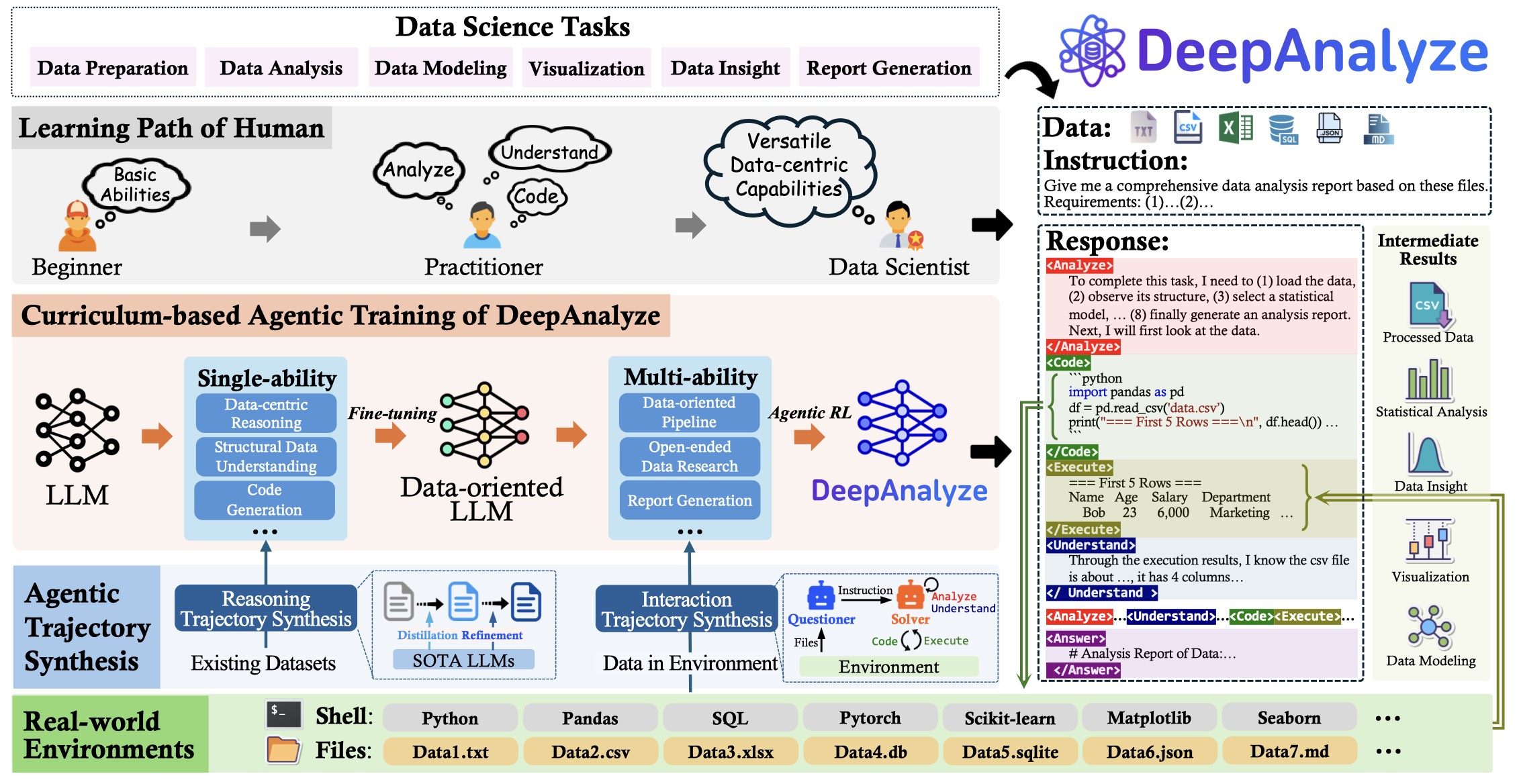
Autonomous data science, from raw data sources to analyst-grade deep research reports, has been a long-standing challenge, and is now becoming feasible with the emergence of powerful large language models (LLMs). Recent workflow-based data agents have shown promising results on specific data tasks but remain fundamentally limited in achieving fully autonomous data science due to their reliance on predefined workflows. In this paper, we introduce DeepAnalyze-8B, the first agentic LLM designed for autonomous data science, capable of automatically completing the end-toend pipeline from data sources to analyst-grade deep research reports. To tackle high-complexity data science tasks, we propose a curriculum-based agentic training paradigm that emulates the learning trajectory of human data scientists, enabling LLMs to progressively acquire and integrate multiple capabilities in real-world environments. We also introduce a data-grounded trajectory synthesis framework that constructs high-quality training data. Through agentic training, DeepAnalyze learns to perform a broad spectrum of data tasks, ranging from data question answering and specialized analytical tasks to open-ended data research. Experiments demonstrate that, with only 8B parameters, DeepAnalyze outperforms previous workflow-based agents built on most advanced proprietary LLMs. The model, code, and training data of DeepAnalyze are open-sourced, paving the way toward autonomous data science.
Introducing DeepAnalyze
DeepAnalyze automates the entire data science pipeline, such as specific data tasks and open-ended data research, offering a “one-size-fits-all” solution for data science tasks.
To achieve this, we propose:
- Curriculum-based agentic training: Guide LLM from mastering individual single abilities to developing comprehensive abilities in real-world environments through a progressive easy-to-difficult schedule.
- Data-grounded trajectory synthesis: Automatically generates high-quality reasoning and interaction trajectories to provide effective guidance within the vast solution space.
More details refer to DeepAnalyze's paper.
DeepAnalyze Deep Research Cases
- Case 1
- Case 2
- Case 3
- Case 4
- Case 5
- Case 6
- Case 7
- Case 8
- Case 9
- Case 10
- Case 11
- Case 12
- Case 13
- Case 14
- Case 15
- Case 16
- Case 17
- Case 18
- Case 19
- Case 20
- Case 21
- Case 22
- Case 23
- Case 24
- Case 25
- Case 26
- Case 27
- Case 28
- Case 29
- Case 30
- Case 31
- Case 32
- Case 33
- Case 34
- Case 35
- Case 36
- Case 37
- Case 38
- Case 39
- Case 40
- Case 41
- Case 42
- Case 43
- Case 44
- Case 45
- Case 46
- Case 47
- Case 48
- Case 49
- Case 50
- Case 51
- Case 52
- Case 53
- Case 54
- Case 55
- Case 56
- Case 57
- Case 58
- Case 59
- Case 60
- Case 61
- Case 62
- Case 63
- Case 64
- Case 65
- Case 66
- Case 67
- Case 68
- Case 69
- Case 70
- Case 71
- Case 72
- Case 73
- Case 74
- Case 75
- Case 76
- Case 77
- Case 78
- Case 79
- Case 80
- Case 81
- Case 82
- Case 83
- Case 84
- Case 85
- Case 86
- Case 87
- Case 88
- Case 89
- Case 90
- Case 91
- Case 92
- Case 93
- Case 94
- Case 95
- Case 96
- Case 97
- Case 98
- Case 99
- Case 100
Instruction:
Analyze the payment processing dataset to prepare it for fee optimization analysis. Your task is to research and document the methodology for merging transaction data from payments.csv with fee rules from fees.json, merchant metadata from merchant_data.json, and reference data from acquirer_countries.csv and merchant_category_codes.csv. The report should outline strategies for handling complex conditional fee calculations, resolving data inconsistencies across sources, and creating a unified dataset suitable for identifying cost-saving opportunities through optimal acquirer selection and transaction routing.
DeepAnalyze:
import pandas as pd
import json
# First examine the payments.csv structure
print("=== Payments Data Structure ===")
payments_sample = pd.read_csv('payments.csv', nrows=5)
print("Sample rows:")
print(payments_sample.head(2))
print("\nColumns:", list(payments_sample.columns))
print("\nData types:")
print(payments_sample.dtypes)
# Check file sizes and basic stats
file_sizes = {
'payments.csv': 23028.7,
'fees.json': 518.7,
'merchant_data.json': 6.7,
'acquirer_countries.csv': 0.2,
'merchant_category_codes.csv': 26.0
}
print("\nFile sizes (KB):")
for file, size in file_sizes.items():
print(f"{file}: {size:.1f}")
# Examine fees.json structure
print("\n=== Fees Data Structure ===")
with open('fees.json', 'r') as f:
fees_data = json.load(f)
print(f"Number of fee rules: {len(fees_data)}")
print("First fee rule structure:")
print(json.dumps(fees_data[0], indent=2))
# Check merchant_data.json
print("\n=== Merchant Data Structure ===")
with open('merchant_data.json', 'r') as f:
merchant_data = json.load(f)
print(f"Number of merchants: {len(merchant_data)}")
print("Sample merchant record:")
print(json.dumps(merchant_data[0], indent=2))
# Check reference files
print("\n=== Reference Data Samples ===")
acquirer_countries = pd.read_csv('acquirer_countries.csv')
print("\nAcquirer Countries:")
print(acquirer_countries.head(2))
print("\nColumns:", list(acquirer_countries.columns))
mcc_data = pd.read_csv('merchant_category_codes.csv')
print("\nMerchant Category Codes:")
print(mcc_data.head(2))
print("\nColumns:", list(mcc_data.columns))
import pandas as pd
import json
from datetime import datetime
# Load core datasets
payments = pd.read_csv('payments.csv', usecols=[
'psp_reference', 'merchant', 'card_scheme', 'is_credit',
'eur_amount', 'issuing_country', 'acquirer_country', 'aci'
])
with open('fees.json') as f:
fee_rules = json.load(f)
with open('merchant_data.json') as f:
merchant_data = json.load(f)
acquirer_countries = pd.read_csv('acquirer_countries.csv')
mcc_data = pd.read_csv('merchant_category_codes.csv')
# Create merchant attribute mapping
merchant_attrs = pd.DataFrame(merchant_data)
merchant_map = merchant_attrs.set_index('merchant').to_dict('index')
# Process acquirer countries
acquirer_country_map = dict(zip(acquirer_countries['acquirer'],
acquirer_countries['country_code']))
# Fee rule evaluation function
def matches_rule(transaction, merchant, rule):
"""Check if transaction matches a fee rule"""
# Card scheme match
if rule['card_scheme'] and transaction['card_scheme'] != rule['card_scheme']:
return False
# Account type match
if rule['account_type'] and merchant['account_type'] not in rule['account_type']:
return False
# Merchant category match
if rule['merchant_category_code'] and merchant['merchant_category_code'] not in rule['merchant_category_code']:
return False
# ACI match
if rule['aci'] and transaction['aci'] not in rule['aci']:
return False
# Intracountry check
if rule['intracountry'] is not None:
is_intracountry = transaction['issuing_country'] == transaction['acquirer_country']
if rule['intracountry'] != is_intracountry:
return False
return True
# Test with sample transaction
sample_txn = payments.iloc[0].to_dict()
sample_merchant = merchant_map[sample_txn['merchant']]
print("\nSample Transaction Fee Matching:")
for rule in fee_rules[:3]:
if matches_rule(sample_txn, sample_merchant, rule):
print(f"Rule {rule['ID']} applies")
# Create initial merged dataset (sample)
print("\nCreating merged dataset sample...")
payments['merchant_attr'] = payments['merchant'].map(merchant_map)
payments['acquirer_country_code'] = payments['acquirer_country'].map(acquirer_country_map)
# Show merged structure
print("\nMerged Data Structure:")
print(payments[['psp_reference', 'merchant', 'card_scheme', 'acquirer_country_code']].head(2))
import pandas as pd
import numpy as np
from datetime import datetime
# Load data with optimized dtypes
payments = pd.read_csv('payments.csv', usecols=[
'psp_reference', 'merchant', 'card_scheme', 'is_credit',
'eur_amount', 'issuing_country', 'acquirer_country', 'aci', 'year', 'day_of_year'
], dtype={
'psp_reference': 'int64',
'merchant': 'category',
'card_scheme': 'category',
'is_credit': 'bool',
'eur_amount': 'float32',
'issuing_country': 'category',
'acquirer_country': 'category',
'aci': 'category',
'year': 'int16',
'day_of_year': 'int16'
})
# Load reference data
with open('fees.json') as f:
fee_rules = json.load(f)
with open('merchant_data.json') as f:
merchant_data = json.load(f)
acquirer_countries = pd.read_csv('acquirer_countries.csv')
# Create optimized mappings
merchant_map = pd.Series(merchant_data).to_dict('index')
acquirer_country_map = dict(zip(acquirer_countries['acquirer'],
acquirer_countries['country_code']))
# Enhanced fee rule matching with null handling
def rule_applies(rule, transaction, merchant):
"""Improved rule matching with null handling"""
# Card scheme check
if rule.get('card_scheme') and transaction['card_scheme'] != rule['card_scheme']:
return False
# Account type check (empty list means apply to all)
if rule.get('account_type') and merchant.get('account_type') not in rule['account_type']:
return False
# Merchant category check
if rule.get('merchant_category_code') and merchant.get('merchant_category_code') not in rule['merchant_category_code']:
return False
# ACI check
if rule.get('aci') and transaction['aci'] not in rule['aci']:
return False
# Intracountry check
if rule.get('intracountry') is not None:
is_intracountry = transaction['issuing_country'] == transaction['acquirer_country']
if rule['intracountry'] != is_intracountry:
return False
return True
# Pre-filter rules by common attributes
card_scheme_rules = {r['ID'] for r in fee_rules if not r.get('card_scheme')}
account_type_rules = {}
for r in fee_rules:
at = r.get('account_type')
account_type_rules[at] = account_type_rules.get(at, []) + [r['ID']]
# Sample processing function
def process_batch(transactions, merchant_map):
results = []
for _, txn in transactions.iterrows():
merchant = merchant_map.get(txn['merchant'])
if not merchant:
continue
applicable_rules = []
for rule_id in card_scheme_rules:
rule = next((r for r in fee_rules if r['ID'] == rule_id), None)
if rule and rule_applies(rule, txn, merchant):
applicable_rules.append(rule)
results.append({
'psp_reference': txn['psp_reference'],
'applicable_rules': len(applicable_rules),
'merchant': txn['merchant']
})
return pd.DataFrame(results)
# Test with sample
print("Processing sample batch...")
sample_results = process_batch(payments.head(1000), merchant_map)
print("\nApplicable Rules per Transaction:")
print(sample_results['applicable_rules'].value_counts())
import json
import pandas as pd
import numpy as np
from datetime import datetime
# Load data with optimized dtypes
payments = pd.read_csv('payments.csv', usecols=[
'psp_reference', 'merchant', 'card_scheme', 'is_credit',
'eur_amount', 'issuing_country', 'acquirer_country', 'aci', 'year', 'day_of_year'
], dtype={
'psp_reference': 'int64',
'merchant': 'category',
'card_scheme': 'category',
'is_credit': 'bool',
'eur_amount': 'float32',
'issuing_country': 'category',
'acquirer_country': 'category',
'aci': 'category',
'year': 'int16',
'day_of_year': 'int16'
})
# Load reference data
with open('fees.json') as f:
fee_rules = json.load(f)
with open('merchant_data.json') as f:
merchant_data = json.load(f)
acquirer_countries = pd.read_csv('acquirer_countries.csv')
# Create optimized mappings
merchant_map = pd.Series(merchant_data).to_dict('index')
acquirer_country_map = dict(zip(acquirer_countries['acquirer'],
acquirer_countries['country_code']))
# Enhanced fee rule matching with null handling
def rule_applies(rule, transaction, merchant):
"""Improved rule matching with null handling"""
# Card scheme check
if rule.get('card_scheme') and transaction['card_scheme'] != rule['card_scheme']:
return False
# Account type check (empty list means apply to all)
if rule.get('account_type') and merchant.get('account_type') not in rule['account_type']:
return False
# Merchant category check
if rule.get('merchant_category_code') and merchant.get('merchant_category_code') not in rule['merchant_category_code']:
return False
# ACI check
if rule.get('aci') and transaction['aci'] not in rule['aci']:
return False
# Intracountry check
if rule.get('intracountry') is not None:
is_intracountry = transaction['issuing_country'] == transaction['acquirer_country']
if rule['intracountry'] != is_intracountry:
return False
return True
# Pre-filter rules by common attributes
card_scheme_rules = {r['ID'] for r in fee_rules if not r.get('card_scheme')}
account_type_rules = {}
for r in fee_rules:
at = r.get('account_type')
account_type_rules[at] = account_type_rules.get(at, []) + [r['ID']]
# Sample processing function
def process_batch(transactions, merchant_map):
results = []
for _, txn in transactions.iterrows():
merchant = merchant_map.get(txn['merchant'])
if not merchant:
continue
applicable_rules = []
for rule_id in card_scheme_rules:
rule = next((r for r in fee_rules if r['ID'] == rule_id), None)
if rule and rule_applies(rule, txn, merchant):
applicable_rules.append(rule)
results.append({
'psp_reference': txn['psp_reference'],
'applicable_rules': len(applicable_rules),
'merchant': txn['merchant']
})
return pd.DataFrame(results)
# Test with sample
print("Processing sample batch...")
sample_results = process_batch(payments.head(1000), merchant_map)
print("\nApplicable Rules per Transaction:")
print(sample_results['applicable_rules'].value_counts())
import json
import pandas as pd
import numpy as np
from datetime import datetime
# First inspect merchant_data structure
with open('merchant_data.json') as f:
merchant_data = json.load(f)
print("Merchant data sample structure:")
print(json.dumps(merchant_data[:2], indent=2))
# Create robust merchant mapping function
def create_merchant_map(merchant_list):
"""Handle various merchant data structures"""
merchant_map = {}
for merchant in merchant_list:
if isinstance(merchant, dict):
# Standard dictionary format
merchant_map[merchant.get('merchant', '')] = merchant
elif isinstance(merchant, str):
# Handle string keys directly
merchant_map[merchant] = {}
else:
# Handle other formats
merchant_map[merchant.get('merchant', '')] = merchant
return merchant_map
# Load all data with proper error handling
try:
payments = pd.read_csv('payments.csv', usecols=[
'psp_reference', 'merchant', 'card_scheme', 'is_credit',
'eur_amount', 'issuing_country', 'acquirer_country', 'aci', 'year', 'day_of_year'
], dtype={
'psp_reference': 'int64',
'merchant': 'category',
'card_scheme': 'category',
'is_credit': 'bool',
'eur_amount': 'float32',
'issuing_country': 'category',
'acquirer_country': 'category',
'aci': 'category',
'year': 'int16',
'day_of_year': 'int16'
})
with open('fees.json') as f:
fee_rules = json.load(f)
merchant_map = create_merchant_map(merchant_data)
acquirer_countries = pd.read_csv('acquirer_countries.csv')
print("\nSuccessfully loaded all data with merchant mapping:")
print(f"- {len(payments):,} transactions")
print(f"- {len(fee_rules):,} fee rules")
print(f"- {len(merchant_map):,} merchants mapped")
# Test merchant mapping
sample_merchant = next(iter(merchant_map.values()))
print("\nSample merchant attributes:")
print(sample_merchant)
except Exception as e:
print(f"\nError loading data: {str(e)}")
# Implement fallback loading if primary method fails
print("Attempting alternative loading methods...")
# Alternative loading approach would go here
# ...
import json
import pandas as pd
import numpy as np
from datetime import datetime
# Load all data (using previously validated loading approach)
payments = pd.read_csv('payments.csv', usecols=[
'psp_reference', 'merchant', 'card_scheme', 'is_credit',
'eur_amount', 'issuing_country', 'acquirer_country', 'aci', 'year', 'day_of_year'
], dtype={
'psp_reference': 'int64',
'merchant': 'category',
'card_scheme': 'category',
'is_credit': 'bool',
'eur_amount': 'float32',
'issuing_country': 'category',
'acquirer_country': 'category',
'aci': 'category',
'year': 'int16',
'day_of_year': 'int16'
})
with open('fees.json') as f:
fee_rules = json.load(f)
with open('merchant_data.json') as f:
merchant_data = json.load(f)
acquirer_countries = pd.read_csv('acquirer_countries.csv')
# Create merchant mapping
merchant_map = {m['merchant']: m for m in merchant_data}
# Enhanced fee rule evaluation with attribute handling
def evaluate_fee(transaction, merchant, rule):
"""Comprehensive fee rule evaluation"""
# Basic attribute checks
if rule.get('card_scheme') and transaction['card_scheme'] != rule['card_scheme']:
return None
if rule.get('account_type') and merchant.get('account_type') not in rule['account_type']:
return None
if rule.get('merchant_category_code') and merchant.get('merchant_category_code') not in rule['merchant_category_code']:
return None
if rule.get('aci') and transaction['aci'] not in rule['aci']:
return None
# Intracountry check
if rule.get('intracountry') is not None:
is_intracountry = transaction['issuing_country'] == transaction['acquirer_country']
if rule['intracountry'] != is_intracountry:
return None
# Calculate fee components
fixed = rule.get('fixed_amount', 0)
rate = rule.get('rate', 0)
fee = fixed + (rate * transaction['eur_amount'] / 10000)
return {
'rule_id': rule['ID'],
'fee': fee,
'fixed_amount': fixed,
'rate': rate,
'applicable': True
}
# Process transactions in batches
def process_transactions(transactions, batch_size=1000):
results = []
for i in range(0, len(transactions), batch_size):
batch = transactions.iloc[i:i+batch_size]
batch_results = []
for _, txn in batch.iterrows():
merchant = merchant_map.get(txn['merchant'])
if not merchant:
continue
applicable_rules = []
for rule in fee_rules:
fee_info = evaluate_fee(txn, merchant, rule)
if fee_info:
applicable_rules.append(fee_info)
batch_results.append({
'psp_reference': txn['psp_reference'],
'merchant': txn['merchant'],
'applicable_rules': len(applicable_rules),
'total_fee': sum(r['fee'] for r in applicable_rules) if applicable_rules else 0
})
results.extend(batch_results)
return pd.DataFrame(results)
# Process sample batch
print("Processing sample transactions...")
sample_results = process_transactions(payments.head(1000))
print("\nSample Results:")
print(f"Processed {len(sample_results)} transactions")
print("Fee distribution:")
print(sample_results['total_fee'].describe())
# Save results for further analysis
sample_results.to_csv('sample_fee_analysis.csv', index=False)
print("\nSaved sample results to 'sample_fee_analysis.csv'")
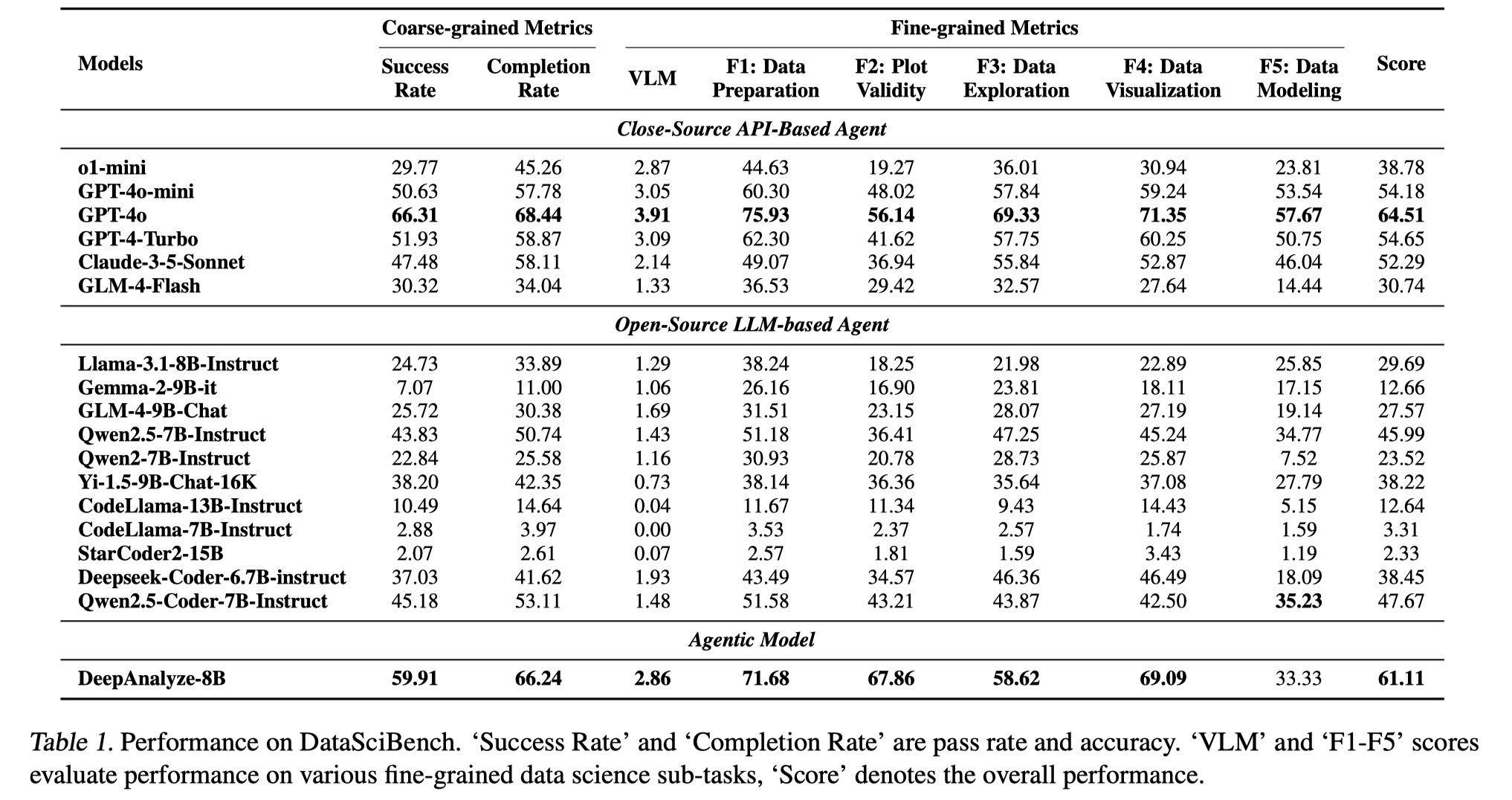
Performance of DeepAnalyze 🎈
1. End-to-end Data Pipeline
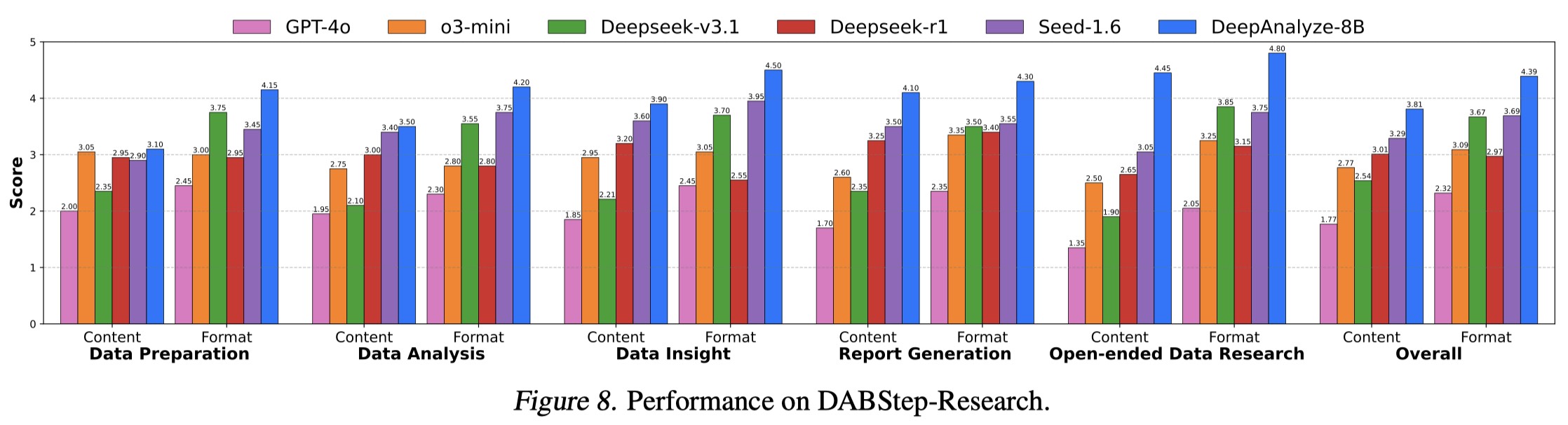
2. Data-oriented Deep Research
3. Data Analysis
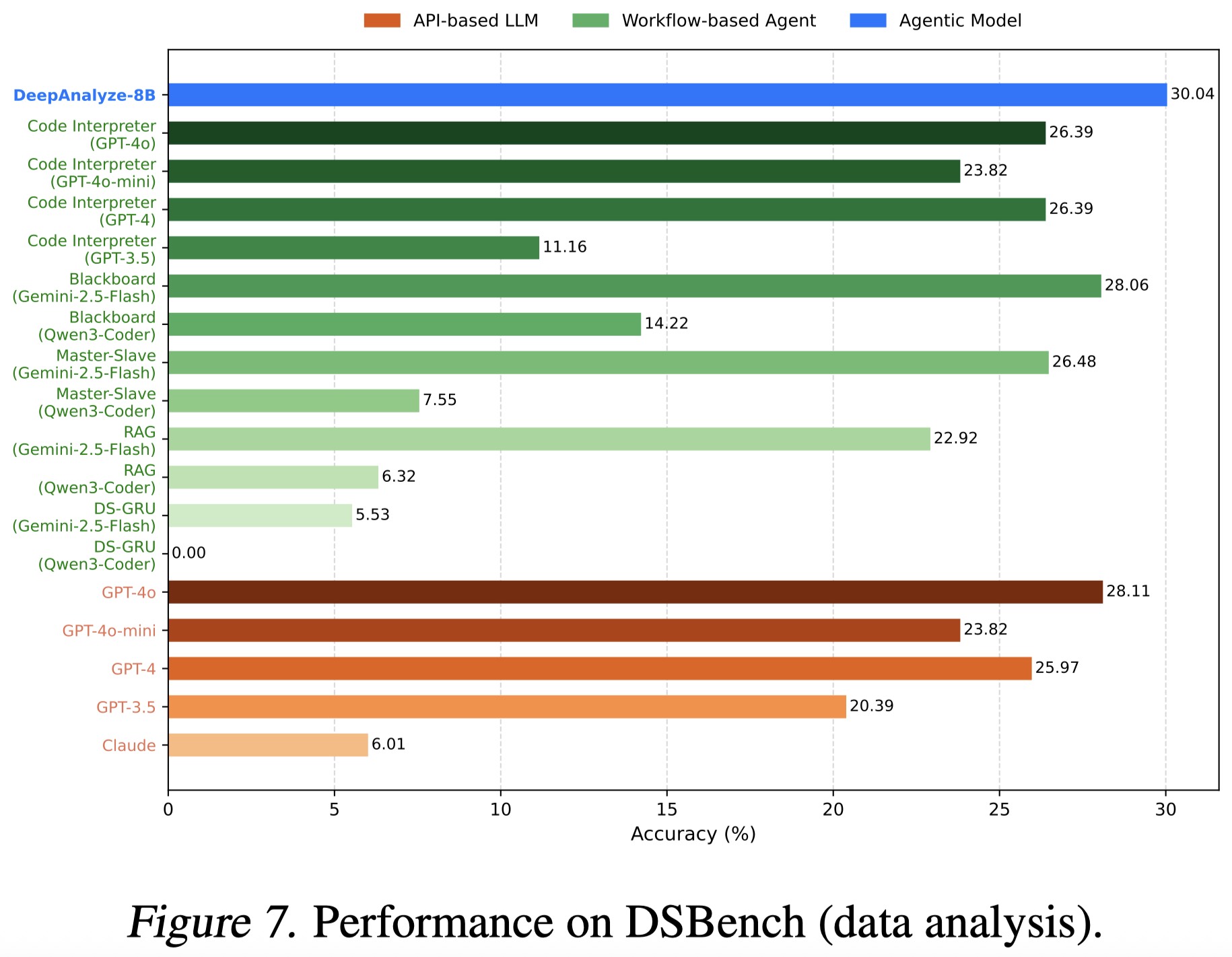
4. Data Modeling
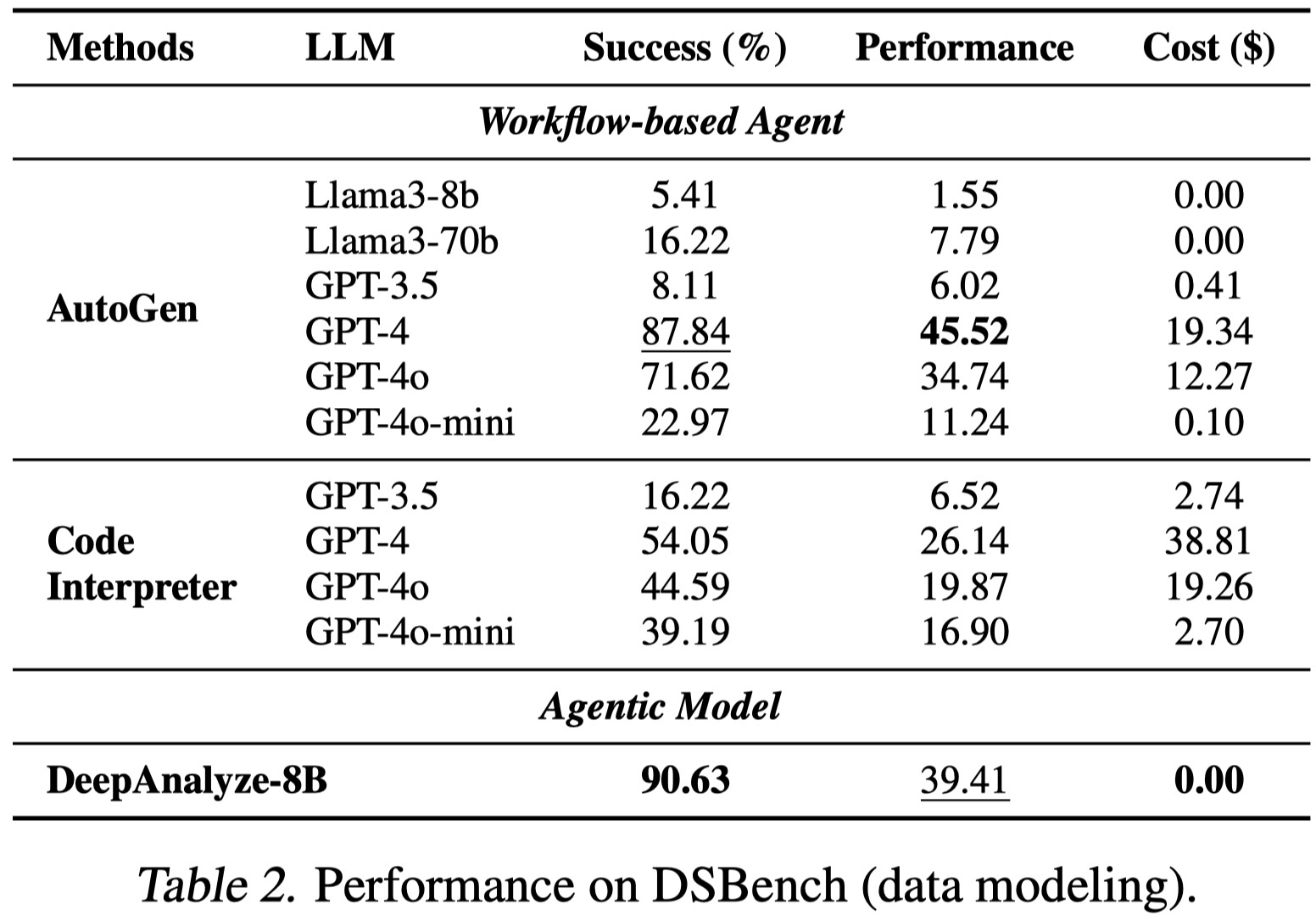
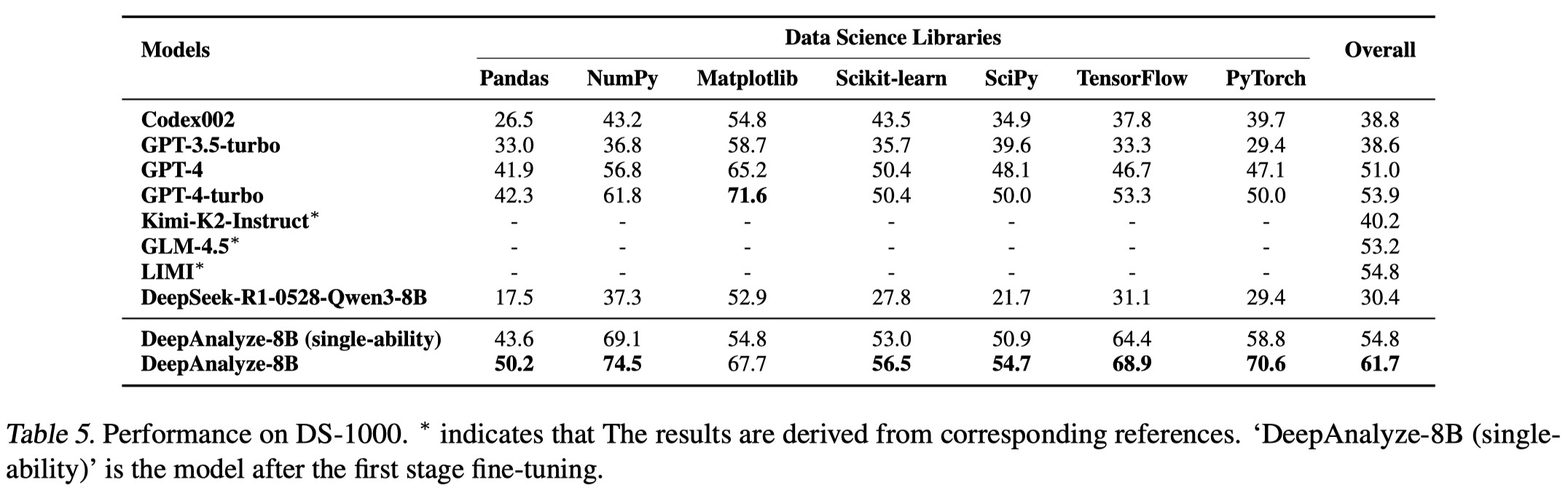
5. Data Science Code Generation
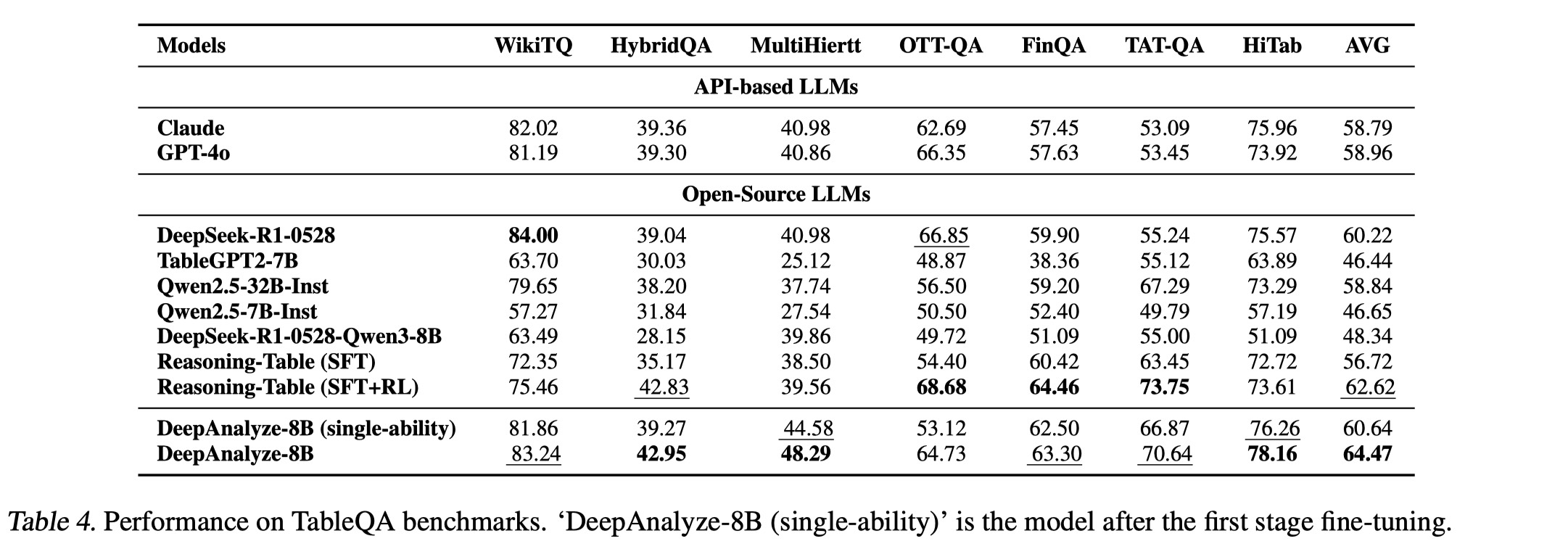
6. Structured Data Understanding
BibTeX
@misc{deepanalyze,
title={DeepAnalyze: Agentic Large Language Models for Autonomous Data Science},
author={Shaolei Zhang and Ju Fan and Meihao Fan and Guoliang Li and Xiaoyong Du},
year={2025},
eprint={2510.16872},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2510.16872},
}